안녕하세요. 어미새입니다.
오늘은 합의 알고리즘의 등장 배경과, 비트코인 네트워크에서 사용되는 합의 알고리즘인, 작업증명(Pow)방식에 대한 개념 정리를 해보도록 하겠습니다.
합의 알고리즘
네트워크에 연결된 사용자는 그 누구도 신뢰할 수 없는 사용자입니다. 분산 처리 시스템 및 탈중앙화 시스템은 중앙에서 관리하는 기구나 단체가 없기 때문에 시스템 내부에서 데이터를 검증하고 관리할 수 있는 수단이나 방법이 필요합니다.
비트코인에서도 마찬가지로 어떤 트랜잭션이 발생했을 경우 해당 트랜잭션이 유효한 트랜잭션인지에 대한 합의 방법이 필요하며, 새로운 블록이 진짜인지, 가자짜인지에 대한 검증이 필요합니다.
올바른 데이터의 검증은 네트워크의 신뢰도를 향상 시키며, 신뢰도가 높은 시스템일수록 시스템의 가치는 상승하게 됩니다. 합의 알고리즘에 대해 더 자세히 알고 싶으신분은 제가 이전에 작성한 합의 알고리즘편을 참조하시길 바랍니다.
비트코인 시스템에서는 비잔티움 장군의 문제점 및 네트워크의 신뢰도 향상을 위해 작업증명 방식(PoW)의 합의 알고리즘을 사용하고 있습니다. 지금부터 PoW가 무엇인지에 대해 상세히 알아보도록 하겠습니다.
PoW(Proof-of-Work)
PoW에 대한 개념을 정리하기 위해서는 비트코인 마이닝 원리에 대한 선행학습이 필요합니다.
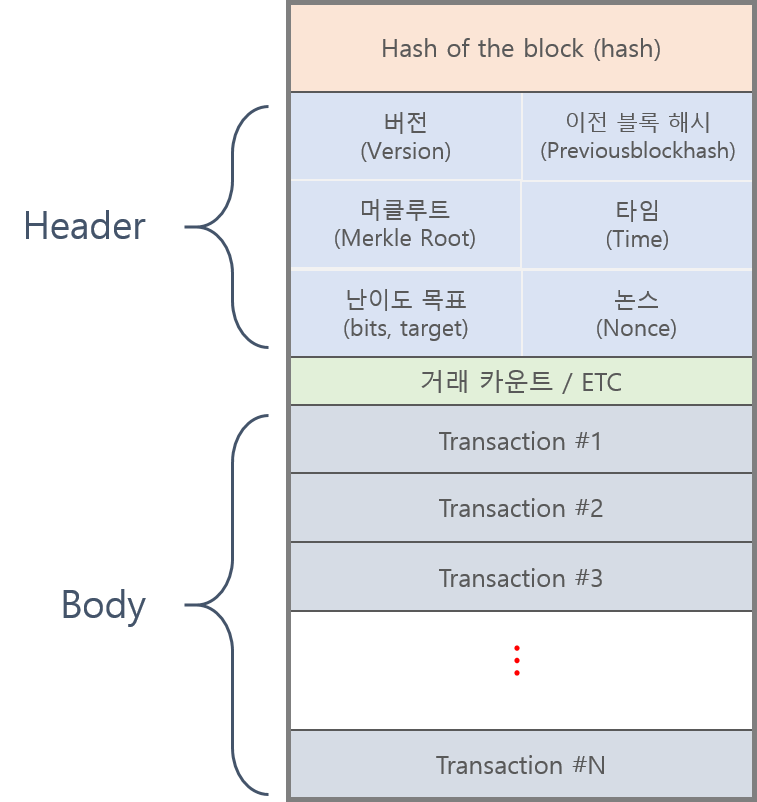
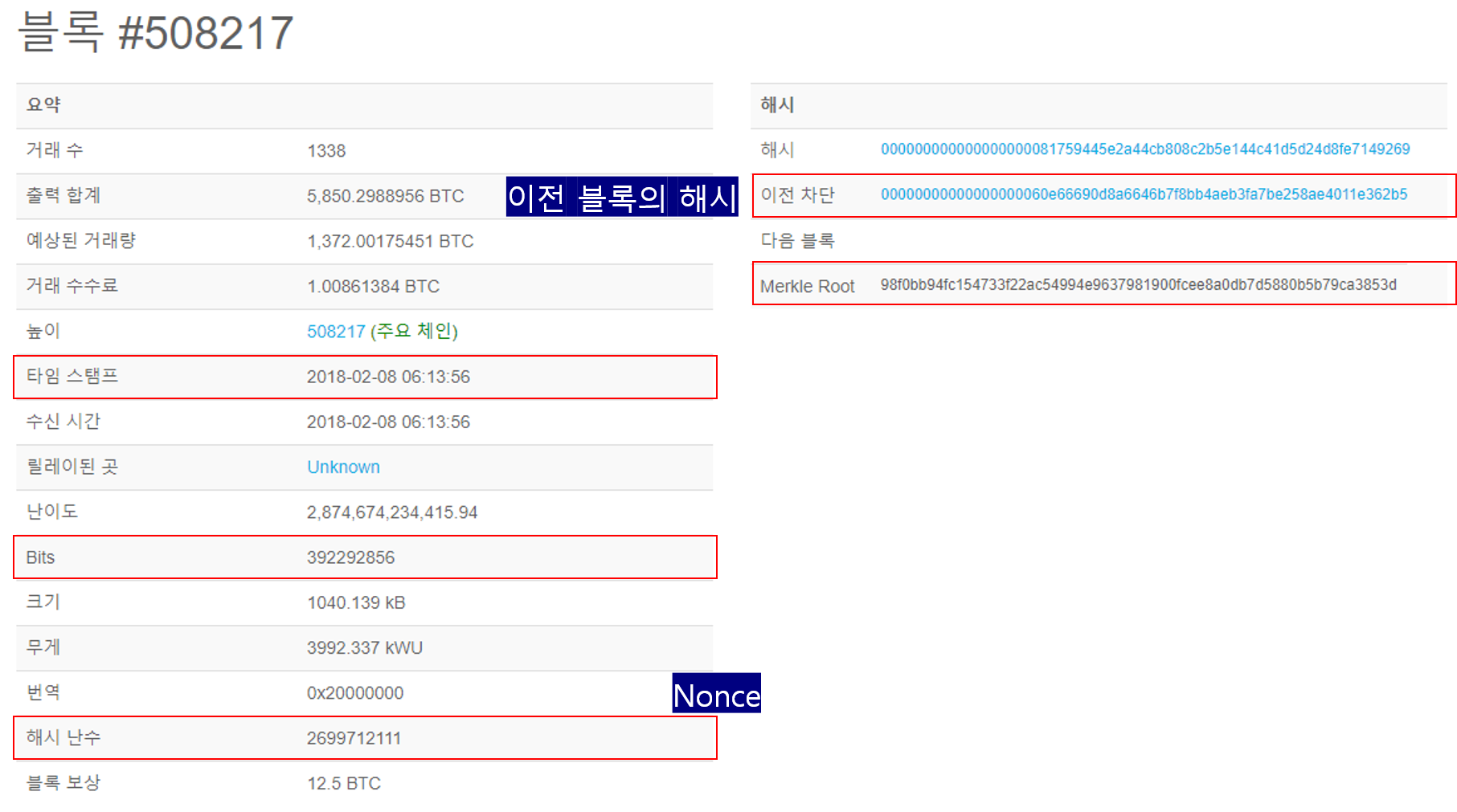
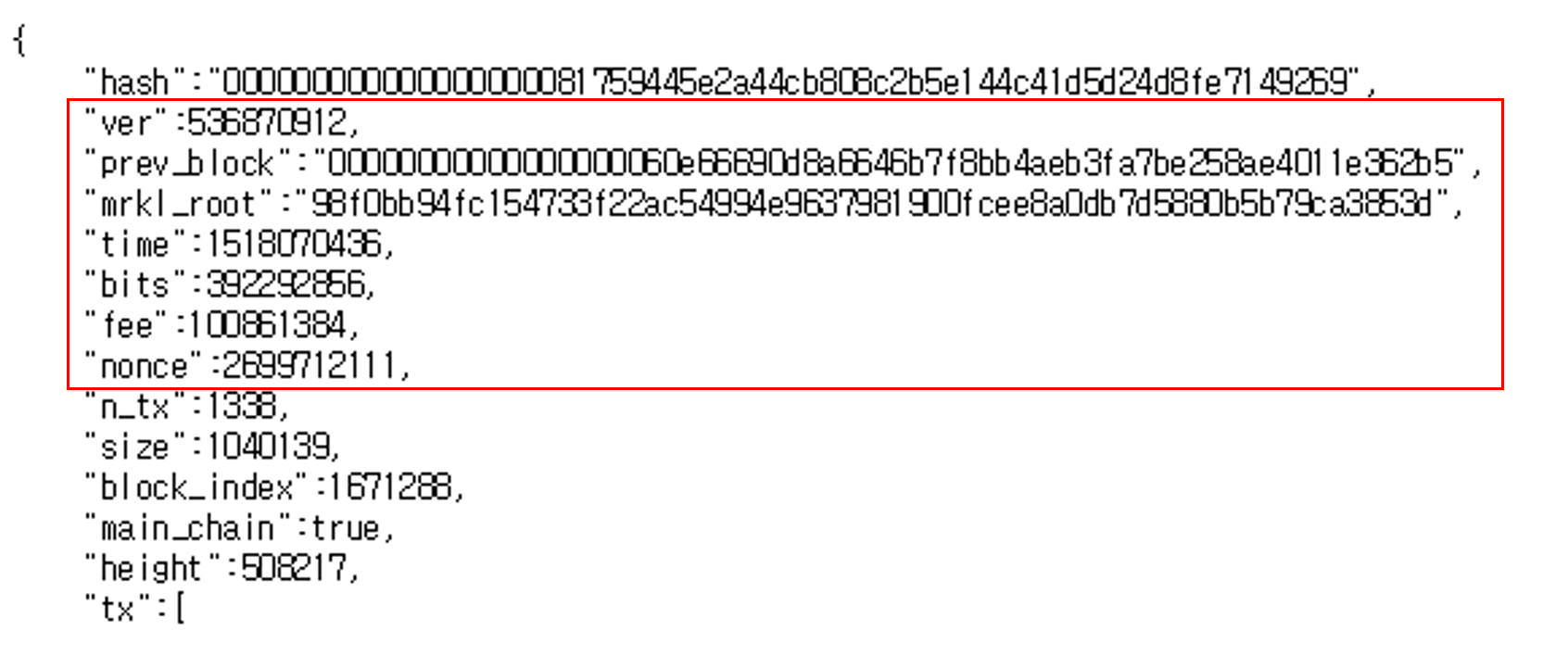
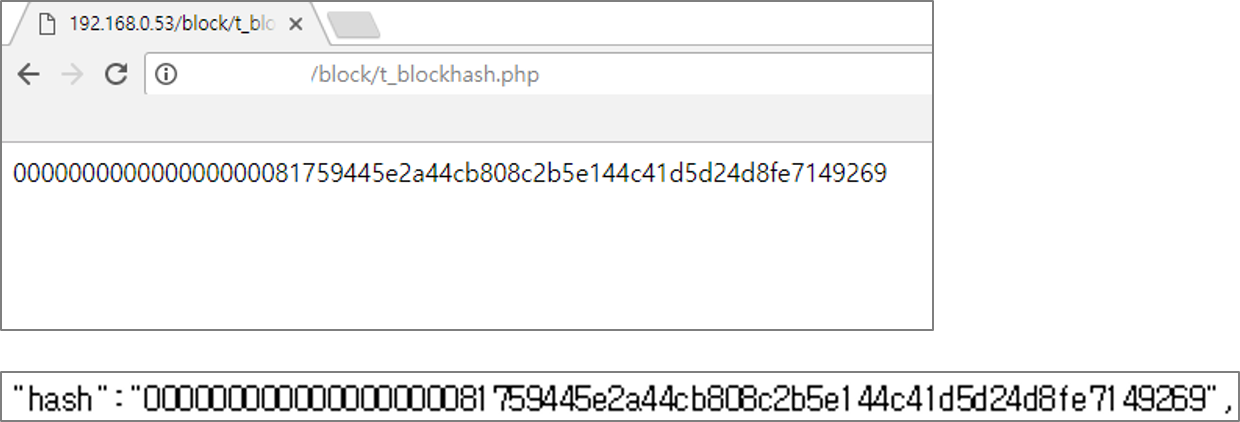
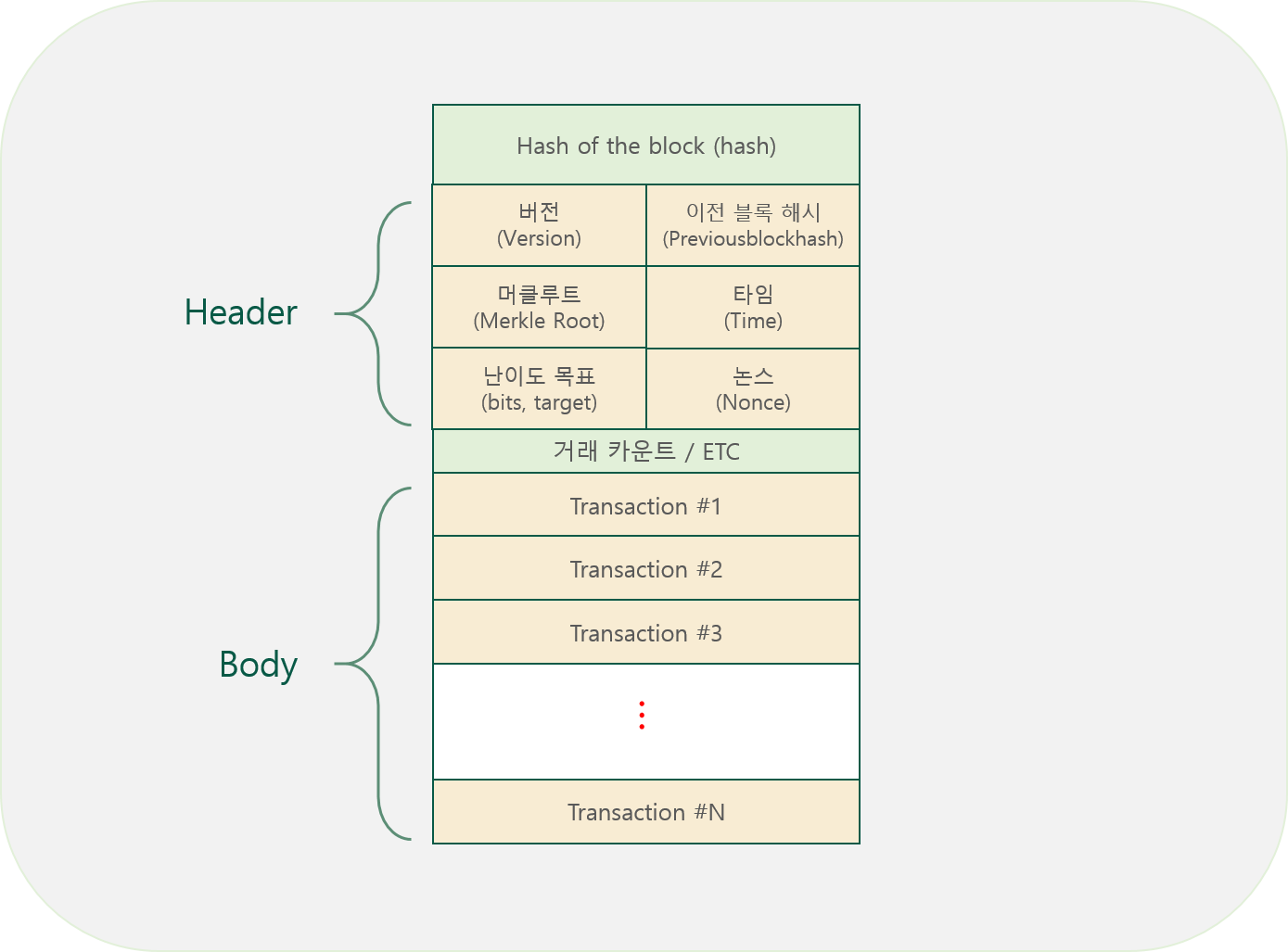
마이닝(채굴)이란 일종의 수학문제를 푸는것과 같습니다. 임이의 nonce 값을 대입하여 블록 해시 결과 값을 생성하고, 생성된 결과 값이 target 보다 작을 경우 새로운 블록으로 인정받을 수 있습니다. 새로운 블록을 생성한 채굴자는 블록을 생성한 댓가로 신규로 발행되는 비트코인의 수량 및 거래 수수로를 '보상'으로 받게됩니다.
현재 시점을 기준으로 '보상'받는 금액은 1억원이 넘는 아주 큰 금액입니다. 채굴자(마이너)는 이러한 보상을 받기 위해서 수학문제를 아주 열심히 풀 수 밖에 없겠죠?

해시함수의 특징때문에 어떤 nonce 값을 대입해야 target보다 작은 블록해시 정보를 찾을 수 있을지는 알 수 없습니다. 즉 올바른 결과 값을 찾기 위해서는 nonce의 값을 0부터 1식 증가 시키면서 target 보다 작은 결과 값이 나올때까지 무한 반복 작업을 수행해야합니다.
이러한 수학문제를 풀이하는 과정을 1초에 몇번이나 수행할 수 있는지에 대한 수치 정보를 해시파워라고 표현하며, 해시파워가 높은 사용자는 더 많은 문제를 풀어낼 수 있습니다. 그리고 문제를 더 많이 풀어낼 수 있는 능력을 보유한 채굴자가 새로운 블록을 찾을 확률이 높습니다!
즉 더 많은 연산을 수행한 채굴자는 더 많은 일을 했다는 의미이며, 확률적으로 많은 문제를 풀었을 경우 블록을 찾을 확률이 높아지며, 더 많은 '보상'을 받게되는거죠!
그렇기 때문에 PoW를 정의할때 더 많은 일을 한 사람에게 더 많은 보상이 주어지는 방식이라고 표현 합니다.
Pow 장단점.
무한 경쟁
채굴을 통해 받을 수 있는 '보상' 금액은 커지면, 채굴자는 자연스럽게 더 많은 보상을 위해서 더 빠른 연산력을 원하게 됩니다. 예를 들어 A라는 채굴자가 '해시 파워'를 높여서 더 많은 보상을 받게되면, 채굴자 B와 C 또한 덩달아서 '해시 파워'를 높이기 시작합니다.
왜냐구요? 보상에서 뒤쳐질 수 없기 때문이죠! 채굴자들은 더 많은 보상을 받기 위해 주변에 있는 채굴자들 보다 더 많은 문제를 풀기 원하고 이러한 문제풀이에 대한 경쟁이 계속 가열화될 수 밖에 없습니다. 그래서 PoW 합의 알고리즘을 경쟁 방식이라고 표현합니다.

여기서 또 한가지 재미있는 사실은 경쟁이 치열해지면서 비트코인 네트워크의 전체 해시파워가 상승하게 됩니다. 즉 문제 풀이 능력이 올라갔기 때문에 '난이도'또한 상향됩니다. (난이도가 상향되지 않으면 10분에 1~2블록을 찾아내야하는 규칙이 무너지기 때문이죠!)
난이도가 상승되면, 자연스럽게 문제풀이에 필요한 연산력이 올라가고, 연산력이 올라간 만큼 컴퓨터의 전력 소모 또한 증가합니다! 과도한 전력소모는 높은 유지비용으로 변환되어, 블록체인 네트워크의 장점중 하나인 저렴한 유지비용이 무색해는 현상이 발생합니다!
하지만 아이러니하게도 경쟁이 심화될수록 비트코인 네트워크의 보안은 강화됩니다..
높은 보안력
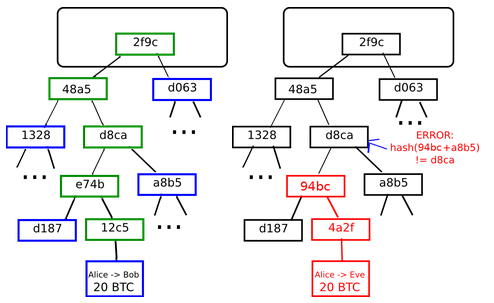
해시 함수의 특징, 그리고 전자 서명의 개념 때문에 블록을 조작하기란 사실상 불가능에 가깝습니다. 만약 블록을 조작했다고 하더라도 해당 블록의 트랜잭션 정보가 변경되면 머클 루트의 결과 값이 변경되고, 머클 루트의 결과 값이 변경되면, 블록 해시 정보 또한 변경됩니다.
블록 해시 정보가 만약 target 보다 작은 값이라면 상관 없겠지만, target 보다 큰 결과 값이라면 다시 target 보다 작은 블록 해시 정보를 얻기 위하여 무작위로 nonce 값을 대입하여 새로운 블록 해시 정보를 얻어야만합니다.
이러한 작업을 수행하는 도중 이미 비트코인의 메인 체인은 계속해서 이어져 나가고 있을것입니다. 메인 체인 보다 더 긴 체인을 형성해야지만 조작된 블록이 포함된 체인이 메인 체인으로 인정 받을 수 있음으로 현재 생성되고 있는 메인 체인 보다 더 빠르게 블록을 생성해 나가야합니다.
경쟁이 가속화 되어 조작된 블록이 아닌 정상적인 블록을 생성하기도 어려워지는 시점에는 사실상 블록을 조작하는것이 불가능 해짐으로 보안력이 높아질 수 밖에 없는것입니다.
한줄 요약 : PoW 알고리즘에 의해 사실상 비트코인 거래 정보 조작은 불가능하다!
하지만!
만약에 연산력이 엄청난 진짜! 말도 안되는 울트라 슈퍼캡짱 연산력을 가진 컴퓨터가 1초에도 몇개씩의 블록을 생성할 수 있다면.. 해킹이 가능해집니다.
현재의 암호체계는 결과값을 토대로 입력값을 알 수 는 없지만, 임이의 숫자를 계속 대입하면 언젠가는 입력 값, 즉 키 정보를 알아낼 수 있습니다. 현재의 연산력으로는 100년이 넘는 긴 시간이 필요합니다.
만약 양자학 컴퓨터가 상용화 되면 현재의 암호체계가 무너진다는 의미도 이와 같은 맥락입니다. 너무 연산력이 빨라서 100년은 연산해야된다고 이야기 했던 부분이 무색해지겠죠.. 불과 몇분, 몇시간안에 풀어낸다고합니다!
이상 긴 글 읽어주셔서 감사합니다!
'비트코인 > 합의 알고리즘' 카테고리의 다른 글
| 합의 문제(Consensus Problem), 합의 알고리즘 (0) | 2018.04.06 |
|---|