안녕하세요. 어미새입니다.
이더리움 백서를 쉽게 이해할 수 있도록 풀어서 설명하는 연재물을 작성하고 있습니다. 어느덧 백서의 중반부를 향해 달려가고 있습니다. 혹시 지난 포스팅을 읽지 못하셨던분들은 먼저 아래의 포스팅을 읽어보시는것을 추천드립니다.
Remind
이더리움에서 메시지는 컨트랙트에 의해 생성되며, 컨트랙트가 실행되는 과정, 그리고 그 과정에서 수수료가 소비되는 과정에 대한 내용을 다뤘습니다. (gas 기억하시죠?)
컨트랙트는 특정 조건이 맞았을때 실행되는 프로그램 코드이며, 해당 코드는 EVM 환경에서 작동됩니다. 지난 시간에서 언급되어듯이 악의적인 프로그램을 막기 위해 코드가 실행되는 바이트의 양에 따라 수수료인 gas가 소모되며, 이러한 과정의 프로세스가 어떻게 흘러가는지에 대한 설명으로 이어졌습니다.
스마트 컨트랙트 코드는 정상적으로 수행이 완료되던지, gas가 부족하여 종료되던지, 혹은 오류가 발생하는 시점에서 종료가되며, 비트코인의 부족한 상태 변화와 달리 이더리움에서는 다양한 상태 변화를 가질 수 있다는 것을 설명하였습니다. 또한, 컨트랙트 코드는 연산을 위해 스택, 메모리, 저장소에 접근할 수 있어야 하며, 블록 헤더 데이터 뿐만 아니라 특정 값이나, 메시지 발송자 및 수신되는 메시지의 데이터에 접근할 수 있으며, 결과 값으로 데이터의 바이트 배열을 반환 할 수도 있었습니다.
블록체인과 채굴(Blockchan and Mining)
[그림 - 이더리움 백서]
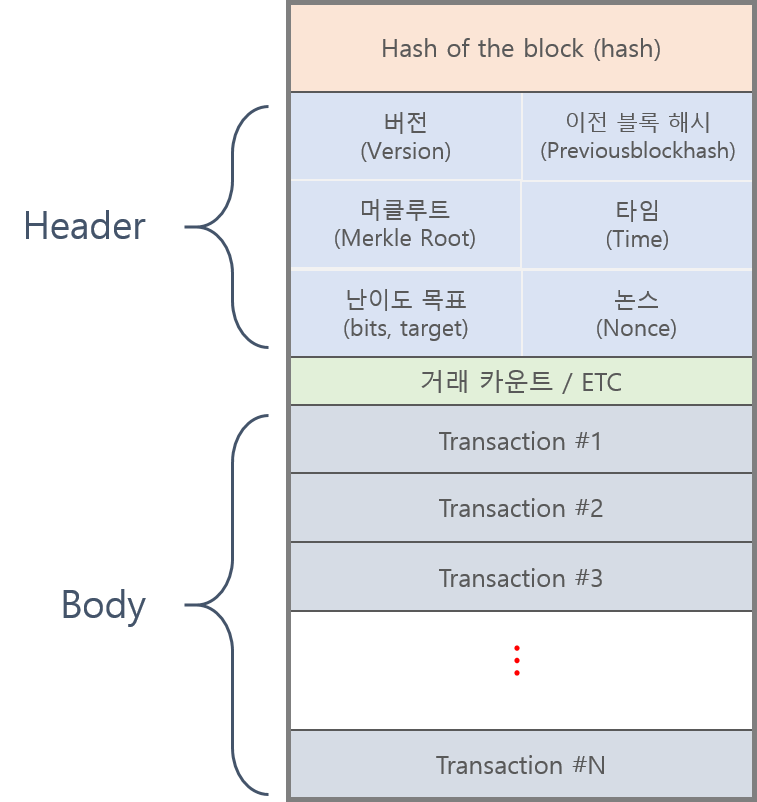
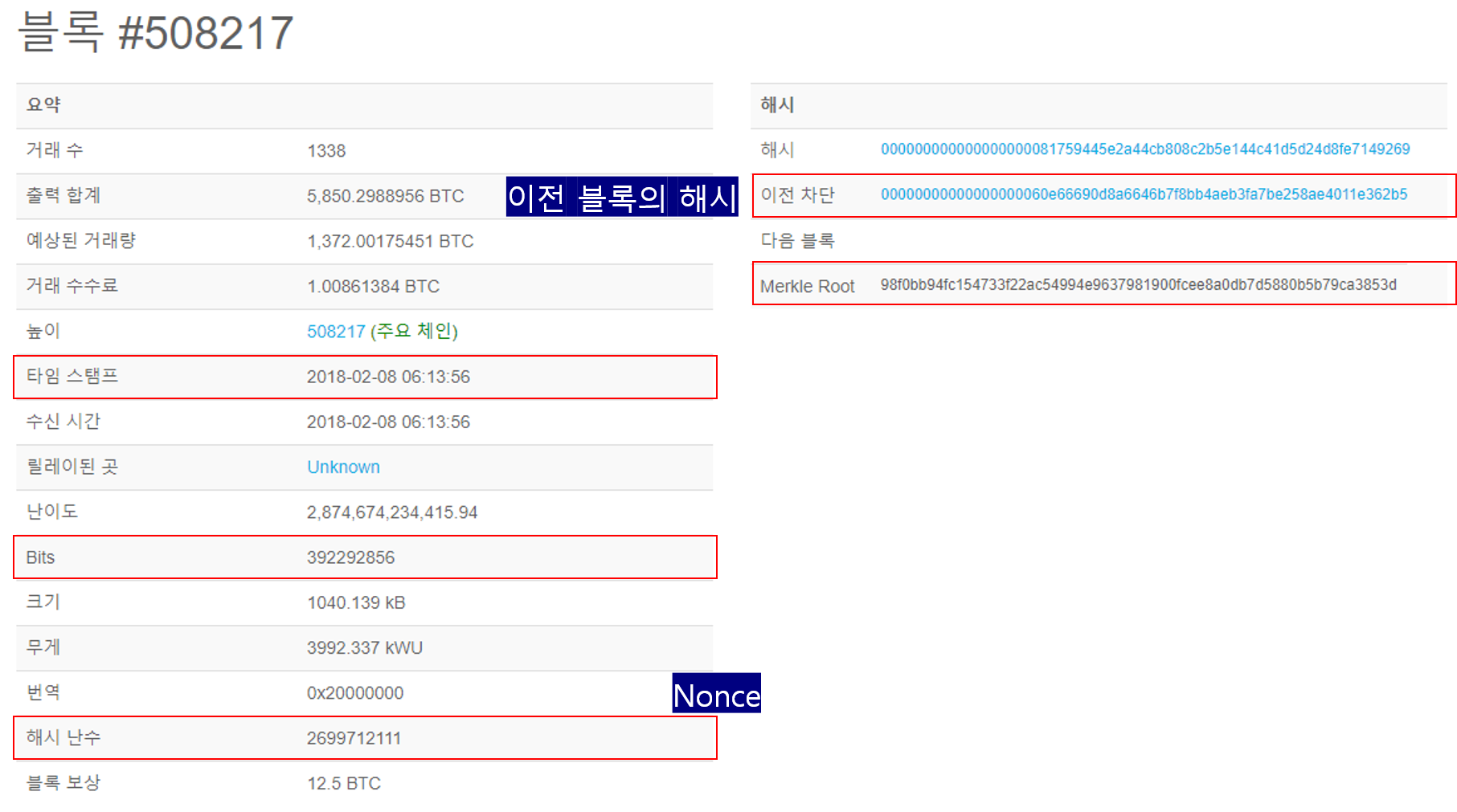
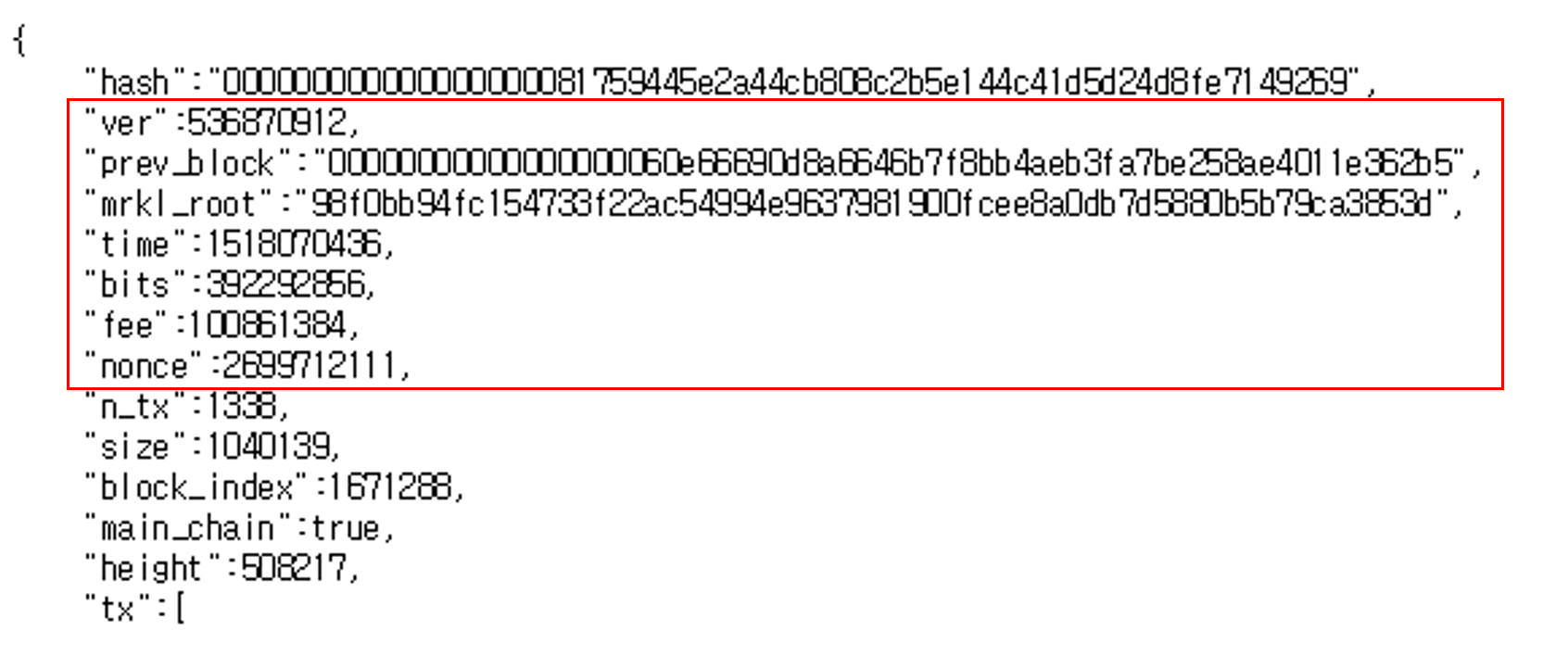
이더리움 블록체인은 여러면에서 비트코인 블록체인과 유사하나, 어느정도 차이점들이 있다. 이더리움과 비트코인에서의 각 블록체인 구조에 대한 주요 차이점으로는 비트코인과는 달리 이더리움 블록은 트랜잭션 리스트와 가장 최근의 상태(state) 복사본을 가지고 있다는 것이다. 그것 외에도, 두개의 다른 값 - 블록 넘버와 difficulty - 이 또한 블록내에 저장된다. 기본적인 이더리움 블록 검증 알고리즘은 다음과 같다.
이더리움의 블록체인은 비트코인 블록체인과 유사하지만 차이점이 있습니다. 이더리움과 비트코인의 블록체인 구조에 대한 주요 차이점은 이더리움의 블록에는 트랜잭션 리스트와 가장 최신의 상태(state) 복사본을 가지고 있으며, 블록 넘버와 difficulry 정보도 블록내에 저장됩니다.
이더리움 블록 검증 알고리즘 시나리오.
생성된 블록에 참조되는 이전 블록이 실제 존재하는 블록인지, 유효한지 확인 한다.
타음 스탬프 값이 이전 블록의 타임 스탬프 값보다 큰 값인지 확인한다, 만약 크다면 15분 이내인지 확인한다.
블록 넘버, difficulty, 트랜잭션 루트, 삼촌 루트, gas 리미트등, 기타 다양한 이더리움 로우 레벨 정보가 유효한지 확인 한다.
블록에 포함된 작업 증명이 유효한지 확인한다.
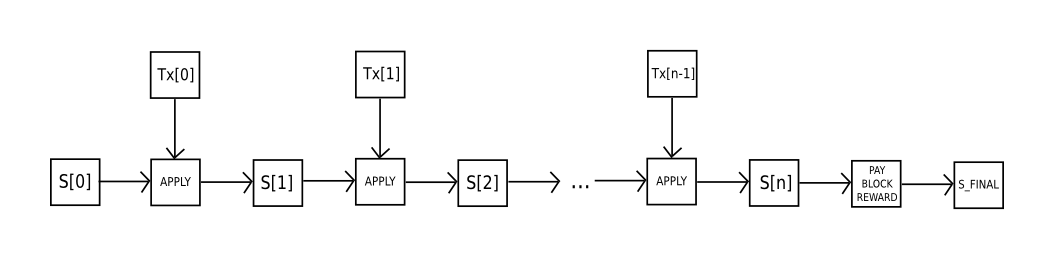
S[0] 상태 정보가, 이전 블록의 마지막 상태(state)라고 가정 하고
TX를 현재 블록의 n개의 트랜잭션을 가지는 리스트라고 가정했을때 0부터 n-1에 대해, S[i+1] = APPLY(S[i], TX[i])로 설정 한다. 이때 어플리케이션이 오류를 반환 하거나, 블록에서 소모된 총 gas가 GASLIMIT를 초과하면 오류를 반환 한다.
채굴자에게 지불된 보상 블록을 S[n] 추가한 후 이것을 S_FINAL이라고 했을때
상태 S_FINAL의 머클 트리 루트가 블록 헤더가 가지고 있는 최종 상태 루트와 같은지 검증한다. 이 값이 같으면 그 블록은 유효한 블록이며, 다른면 유효하지 않은 것으로 판단한다.
이러한 과정은 모든 상태를 각 블록에 저장해야하기때문에 매우 비효율적인 것처럼 보이지만, 효율성 측면에서는 비트코인과 비교할만 하다(즉 비슷하다는 의미인것 같습니다). 그 이유로는 상태가 트리 구조로 저장되고, 모든 블록 뒤에 트리의 작은 부분만이 변경되기 때문이다. 보통, 인접한 두개의 블록간에는 트리의 대부분의 내용이 같으며, 한 번 데이터가 저장되면 포인터(서브트리의 해쉬)를 사용하여 참조될 수 있습니다.
패트리시아 트리(Patricia tree)로 알려진 트리는 머클트리 개념을 수정하여 노드를 효율적으로 삽입하거나, 삭제할 수 있도록 도와줍니다. 또한, 모든 상태 정보가 마지막 블록에 포함되어 있기떄문에 전체 블록체인 히스토리를 모두 저장할 필요가 없으며, 이러한 방법을 만약 비트코인에 적용한다면 5~20배의 저장 공간 절약 효과가 생길것입니다.
물리적인 하드웨어 관점에서 볼 떄, 컨트랙트 코드는 "어디에서" 실행되는지에 대한 의문이 쉽게 들 수 있습니다. 그에 대한 해답은 다음과 같습니다. 컨트랙트 코드를 실행하는 프로세스는 상태 전환 함수 정의의 한 부분이고, 이것은 블록 검증 알고리즘의 부분입니다. 따라서 트랜잭션이 블록 B에 포함되면 그 트랜잭션에 의해 발생할 코드의 실행은 현재 또는 향후에 블록 B를 다운로드 하고 검증하는 모든 노드들에 의해 실행될 것입니다.
어플리케이션(Applications)
이더리움을 이용하여 제작할 수 있는 어플리케이션은 총 세 가지 카테고리의 어플리케이션으로 분류할 수 있습니다.
첫번째 카테고리는 금융 어플리케이션으로 돈과 직접적으로 연관된 컨트랙트를 계약 참여자로 하여 보다 강력하게 설정-관리하게끔하는 어플리케이션입니다. 금융 어플리케이션의 예로는 하위 화폐, 파생상품, 헷지 컨트랙트, 예금용 전자지갑, 유연장, 최종적으로는 고용계약 수준의 것들을 포함할 수 있습니다.
두번째 카테고리는 준(準) 금융 어플리케이션으로 금전이 관련되어 있지만, 상당 부분 비(非) 화폐적인 면이 존재하는 계약을 위한 어플리케이션이 이에 해당됩니다. 준 금융 어플리케이션의 예로는 어려운 연산 문제를 푸는 자에게 자동적으로 포상금이 지급되는 계약입니다.
마지막으로 온라인 투표와 분권형 버넌스(Governance)와 같이 금융과 관련성이 아예 없는 어플리케이션이 있겠습니다.
토큰 시스템(Token Systems)
블록체인토큰시스템(On-blockchain token system)은 하위 화폐(미화/금등과 연동된), 주식과 스마트 자산(Smart Property : 비트코인의 블록체인 상에서 소유권이 컨트롤/관리되는 자산), 위조 불가능한(secure unforgeable) 쿠폰, 기타 토큰 시스템(예 : 인센티브 부여를 위한 포이튼 제도)등, 다양한 형태의 거래시스템을 네트워크 상에서 구현할 수 있도록 도와주는 어플리케이션들을 갖고 있습니다. 이더리움에서 토큰 시스템은 놀랍도록 쉽게 구현할 수 있으며, 토큰 시스템을 이해하는 데에 핵심은 아래와 같습니다.
모든 화폐 혹은 토큰시스템은 근본은 결국 한 가지 오퍼레이션만을 수행하는 데이터베이스이다.
A가 최소 x 단위의 화폐를 보유하고 있는 상태에서, A로부터 x단위의 화폐/토큰을 차감하고, 차감된 x단위의 화폐/토큰을 B에게 지급한다(A가 최종적으로 이 거래를 승인 한다).
이더리움에서 유저는 바로 위의 로직을 컨트랙트에 반영 시키기만하면 됩니다. Serpent에서 토큰 시스템을 실행하는 기본적은 코드는 아래와 같습니다.
def send(to, value):
if self.storage[msg.sender] >= value:
self.storage[msg.sender] = self.storage[msg.sender] - value
self.storage[to] = self.storage[to] + value
def send(to, value) : : sender는 명시되어있지 않지만 보내는 사람이며, to는 받는 사람, value는 값이라고 생각하시면 되겠습니다.
if self.storage[msg.sender] >= value: : 만약 저장된 sender의 값이 보내고자하는 value 즉, 값보다 크거나 같으면 (보내는 수량보다 더 많은 값을 가지고 있어야한다는 의미입니다.)
self.storage[msg.sender] = self.storage[msg.sender] - value : sender의 값을 가져와 value 만큼 차감한 후 sender의 값에 저장합니다.
self.storage[to] = self.storage[to] + value : to 즉, 받는 사람의 값을 가져와 value만큼 더한 후 값을 저장합니다.
위의 코드는 본 백서에서 설명한 은행시스템의 상태변환함수(state transition function)를 아무런 가공없이 그대로적용시킨 것입니다.
토큰 시스템을 개발하기 위해서는 통화의 단위를 정의하고 배급하기 위한 최초의 작업, 또는 더 나아가 여타 컨트랙트들이 계좌의 잔금에 대한 정보 요청을 처리하기 위한 추가 코드가 더 필요할 수 있습니다. 하지만, 그 정도가 토큰 시스템을 만드는 데 필요한 전부입니다. 이론적으로, 이더리움에 기반한 하위화폐 체계로서의 토큰 시스템은 비트코인에 기반환 메타 화폐가 갖고 있지 않은 중요한 특성을 지니고 있을 수 있습니다. (거래비용을 거래 시 사용한 화폐로 직접 지불할 수 있다는 점)
컨트랙트을 집행하기 위해서는 발송인에게 지불해야하는 비용 만큼의 이더 잔고를 유지해야합니다. 그리고 컨트랙트 집행 시 수수료로 받는 내부화폐(하위화폐)를 (상시 돌아가고 있는 내부화폐-이더 거래소에서) 즉각 환전하여 이더 잔고로 충전할 수 있습니다. 컨트랙트 집행 시 수수료로 받는 내부화폐(하위화폐)를 내부화폐-이더 거래소에서 즉각 환전하여 이더 잔고로 충전할 수 있습니다. 유저들은 이더로 그들의 계좌들을 "활성화" 시켜야 하지만, 각 컨트랙트를 통해 얻어지는 만큼의 금액을 이더로 매번 환전할 수 있기 때문에, 한 번 충전도니 이더는 재사용이 가능하다고 볼 수 있습니다.
마무리
이더리움 블록체인은 여러면에서 비트코인 블록체인과 비슷하며 가장 큰 차이점은 블록에 더 많은 정보를 담을 수 있다는 점인것 같습니다. 이더리움의 블록체인은 비트코인의 블록체인과 달리 블록에 트랜잭션 리스트와 가장 최신의 상태(state) 복사본을 가지고 있다는 점이며, 추가로 블록 넘버와, difficulty 정보 또한 블록내에 저장됩니다.
블록의 유효성 검증 과정에서도 비트코인의 경우 타임 스탬프 값이 2시간 이내인지 확인했지만, 이더리움에서는 15분 이내인지 확인하는 과정이 있었습니다. 이 의미는 블록의 평균 생성 시간이 비트코인 보다 훨씬 빠르다는것을 의미합니다.
또한, 이더리움에서는 모든 상태를 각 블록에 저장해야 하기 때문에 비효율적인것처럼 보일 수 있지만, 상태가 트리 구조로 저장되고, 모든 블록 뒤에 트리의 작은 부분만이 변경되기 때문에 효율성 측면에서는 비트코인과 비슷한 수준이지만 더 많은 기능을 수행할 수 있다는 내용을 말하고 싶었던것 같습니다.
이더리움을 통해 개발 가능한 어플리케이션은 크게 3가지 카테고리로 분류할 수 있으며, 금융, 준 금융, 비 금융 어플리케이션으로 나누어 설명하고자 하였습니다. 토큰 시스템은 코인 및 토큰의 차이점에 대하여 작성한 포스팅 문서를 참조하시면 이해하시는데 더 큰 도움이 될것이라고 생각합니다.
어느덧 이더리움 백서 7편입니다. 백서의 흐름으로 이제 중반을 조금 넘은 시점입니다. 대략 11 ~ 12편 정도에서 백서의 내용이 마무리될것 같습니다. 백서의 다음 내용은 파생상품과 가치안전통화, 신원조회 / 평판 시스템(Identity and Reputation Systems), 분산형 파일 저장소(Decentralized File Storage), 탈중앙화된 자율조직(Decentralized Autonomous Organizations), 추가적인 어플리케이션들(Further Applications) 등과 같은 어플리케이션에 대한 설명이 이어집니다.
이더리움에 대한 사전지식 없이 백서를 읽고, 정리하고, 부족한 부분들은 인터넷의 자료를 통해 이해하는 방식으로 백서의 내용을 써가고 있습니다, 그렇다보니 조금 부족한면이 있습니다. 하지만 부족하더라도 이왕 시작한 포스팅 주제이니 끝까지 마무리 해보도록 하겠습니다.
설명을 조금 쉽게 풀어서 해야하는 주제들은 재 포스팅할 예정입니다. 백서편이 빨리 끝나고 조금은 쉬우면서도 재미있게 내용을 풀어보고 싶네요~ (괜히 백서부터 했나..)
이상 긴 글 읽어주셔서 감사합니다!
혹시나 이더리움 백서를 먼저 읽고 싶으신분은 아래의 링크를 통해 이더리움 백서를 먼저 확인해보시는것도 좋을것 같습니다.
[참고문헌]
https://github.com/ethereum/wiki/wiki/%5BKorean%5D-White-Paper#%EC%83%81%ED%83%9C%EB%B3%80%ED%99%98%EC%8B%9C%EC%8A%A4%ED%85%9C%EC%9C%BC%EB%A1%9C%EC%84%9C%EC%9D%98-%EB%B9%84%ED%8A%B8%EC%BD%94%EC%9D%B8bitcoin-as-a-state-transition-system
https://github.com/ethereum/wiki/wiki/White-Paper