안녕하세요. 어미새입니다.
이번 포스팅에서는 지난 시간에 이어서 블록헤더 정보인 '머클 루트'에 대해 알아보도록하겠습니다. 머클 루트의 값은 어떻게 생성되는지, 예제를 통해서 검증하는 시간을 갖도록 하겠습니다.
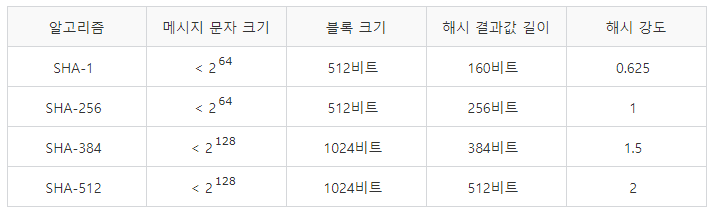
이번 포스팅을 이해하기 위해서는 반드시 해시 함수에 대한 개념이 필요하며, 해시 함수에 대해서 잘 모르시는 분은 아래의 링크를 통해 먼저 해시 함수에 관한 내용을 읽어보시길 바랍니다.
'머클트리(Merkle Tree)' 와 '머클루트(Merkle Root)'
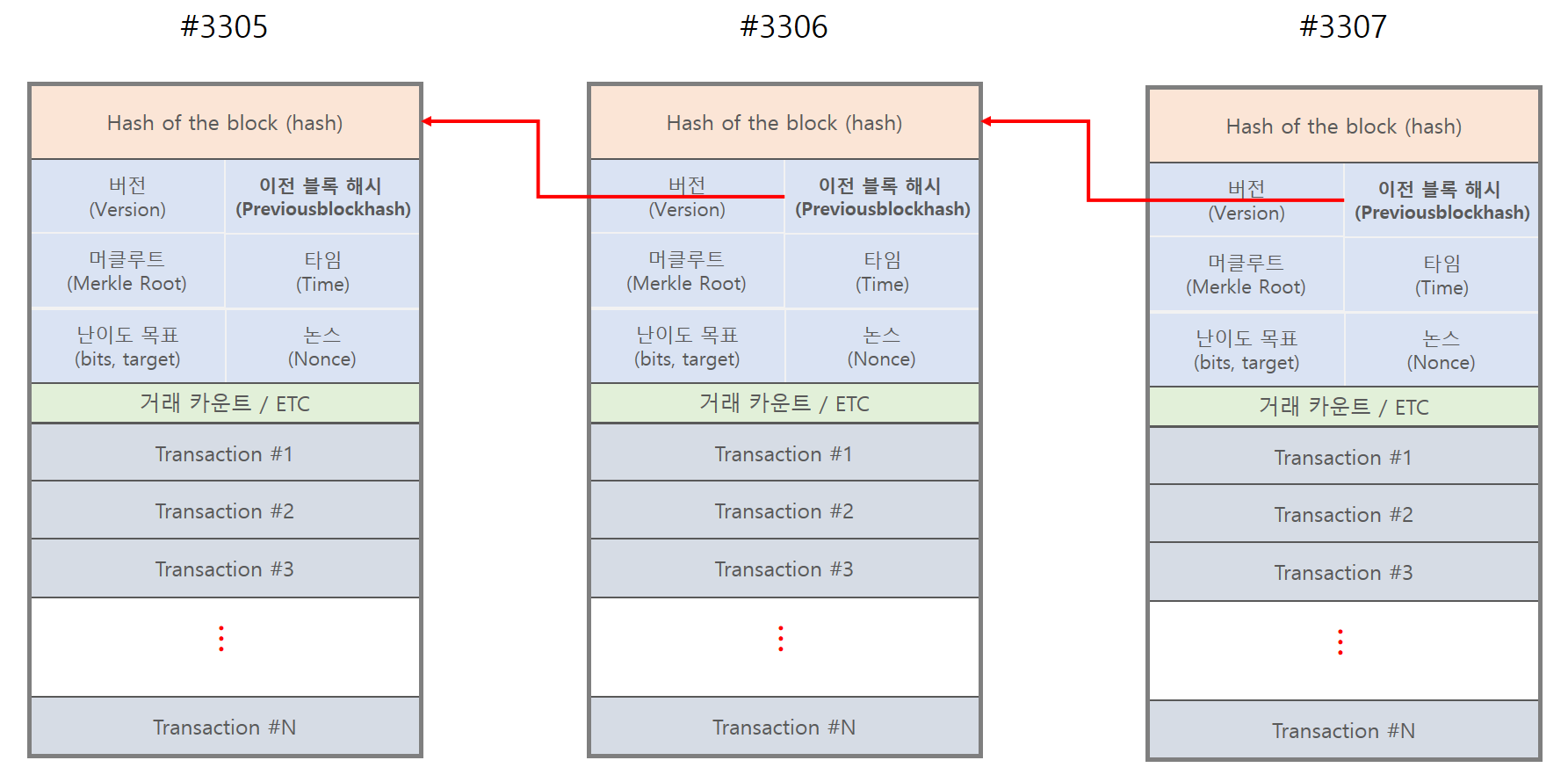
'머클트리(Merkle Tree)' 혹은 '해시트리(Hash Tree)'라는 데이터 구조는 Ralph Merkle이라는 사람이 1979년에 특허를 낸 개념입니다. 머클 트리의 목적은 어떤 블록의 데이터가 분리돼서 전달 될 수 있도록 하는것이며, 블록의 용량을 효율적으로 활용하수 있는 데이터 구조를 가지고 있습니다. 해시 함수의 특징으로 머클 트리 하위 노드들의 해시 값은 상위 노드에 영향을 주며, 어떤 악의적인 유저가 머클 트리 최하위에 있는 트랜잭션 정보를 가짜로 바꿔치기 하면 상위 부모들의 해시 값이 변경되고, 머클 루트 값 또한 변경됩니다. 머클 루트 정보가 변경될 경우 블록 해시 정보 또한 변경되어 해당 블록은 기존의 블록과 전혀 다른 블록으로 인식됩니다.
즉, 머클트리의 목적은 데이터의 간편하고 확실한 인증을 위해 사용합니다.
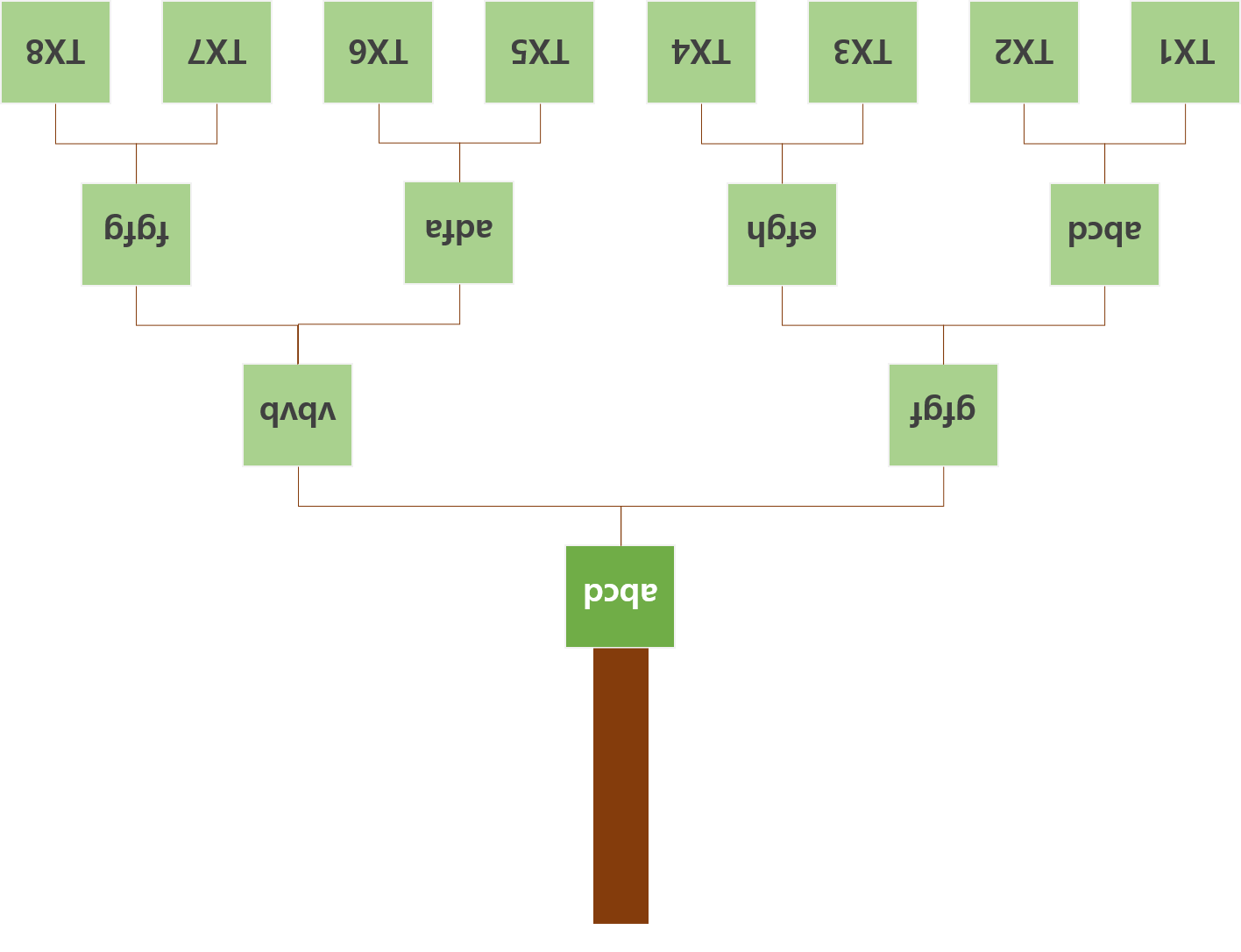
'머클루트(Merkle Root)'란 블록체인의 원소역할을 수행하는 블록의 바디부분에 저장된 트랜잭션들을 머클 트리한 최종 결과 값입니다.
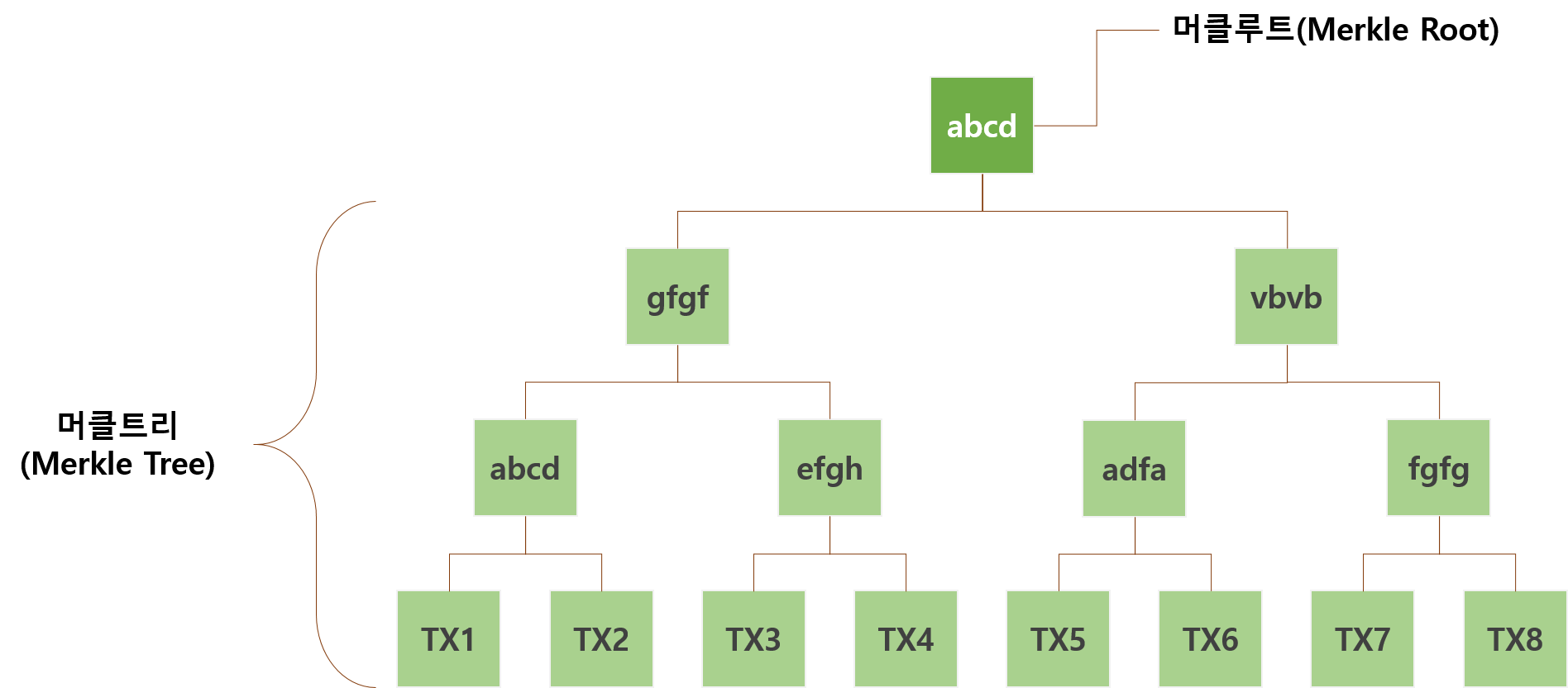
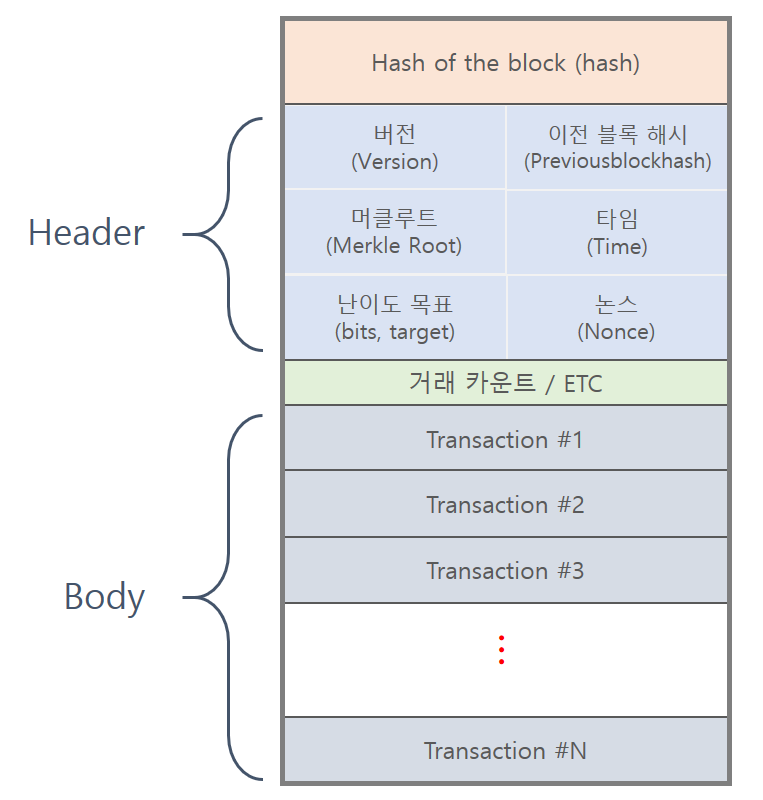
블록의 구조는 크게 블록 헤더와, 블록 바디 정보로 구성되며, 블록의 바디 정보는 트랜잭션, 즉 거래 정보로 구성된다고 설명해드렸습니다. 블록의 바디 정보에 저장된 트랜잭션의 정보들이 유효한지 머클 트리를 통해 검사할 수 있습니다. 그럼 머클 트리는 어떻게 구성되고 최종적으로 머클 루트는 어떻게 만들어질까요?
머클 루트 연산 원리.
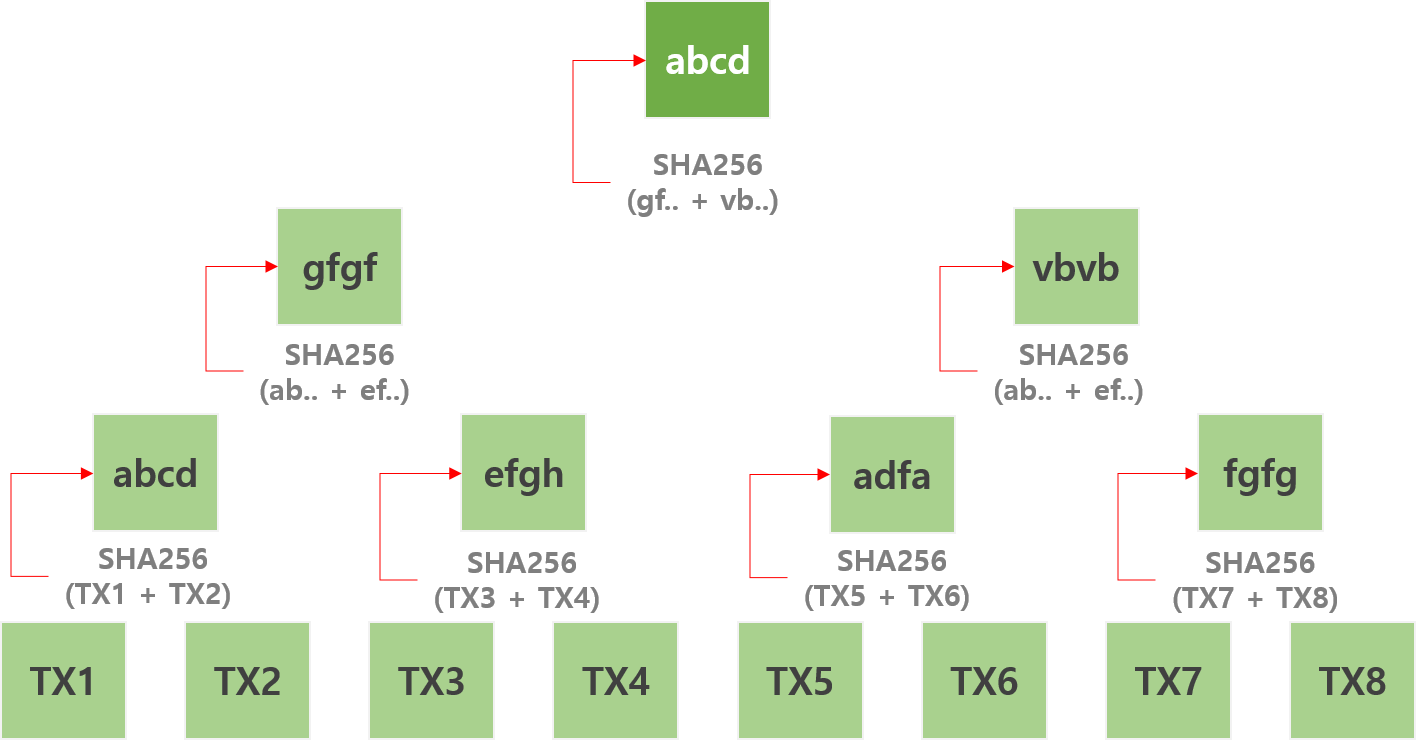
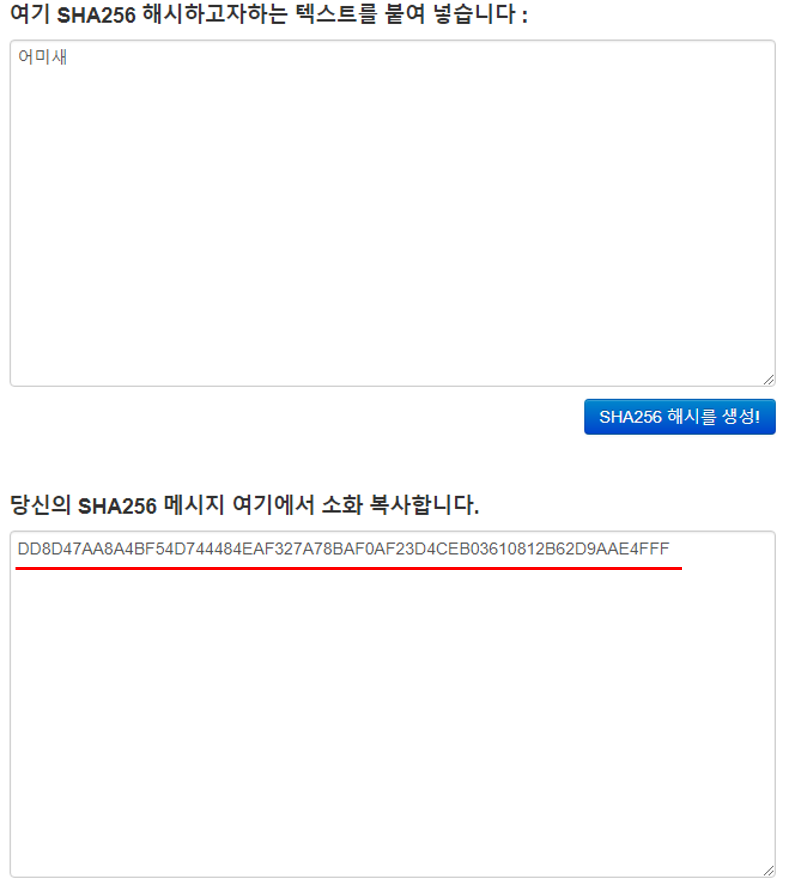
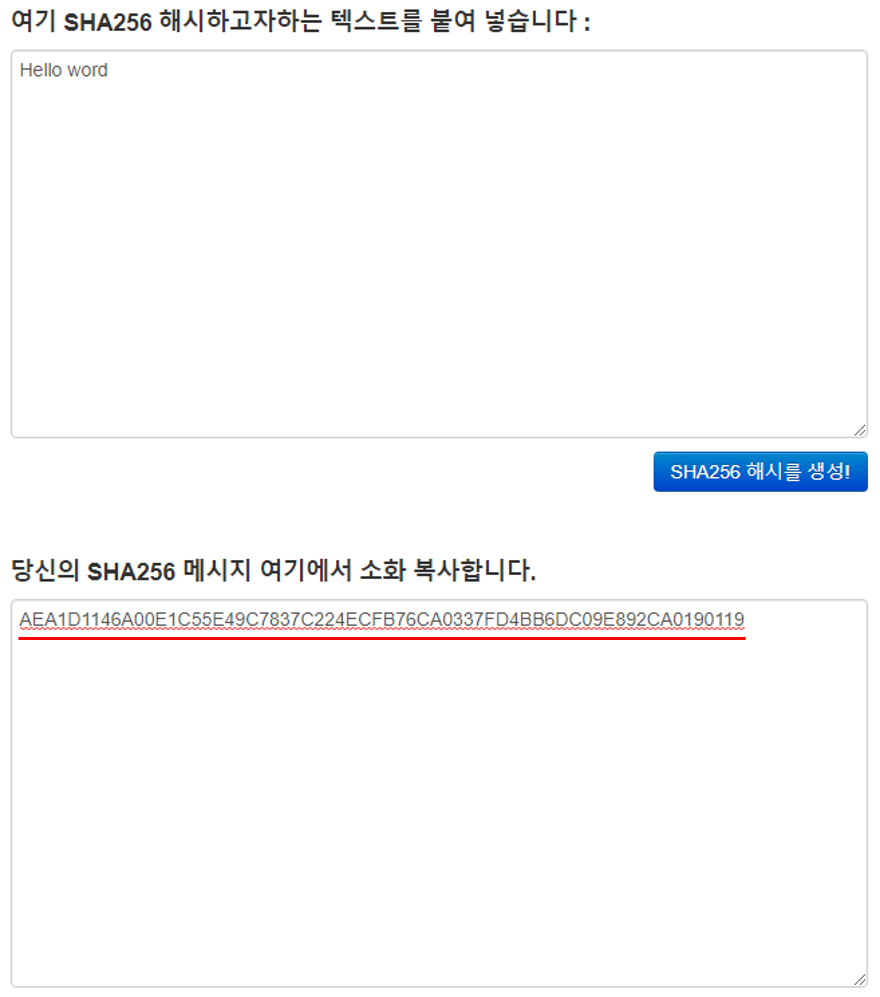
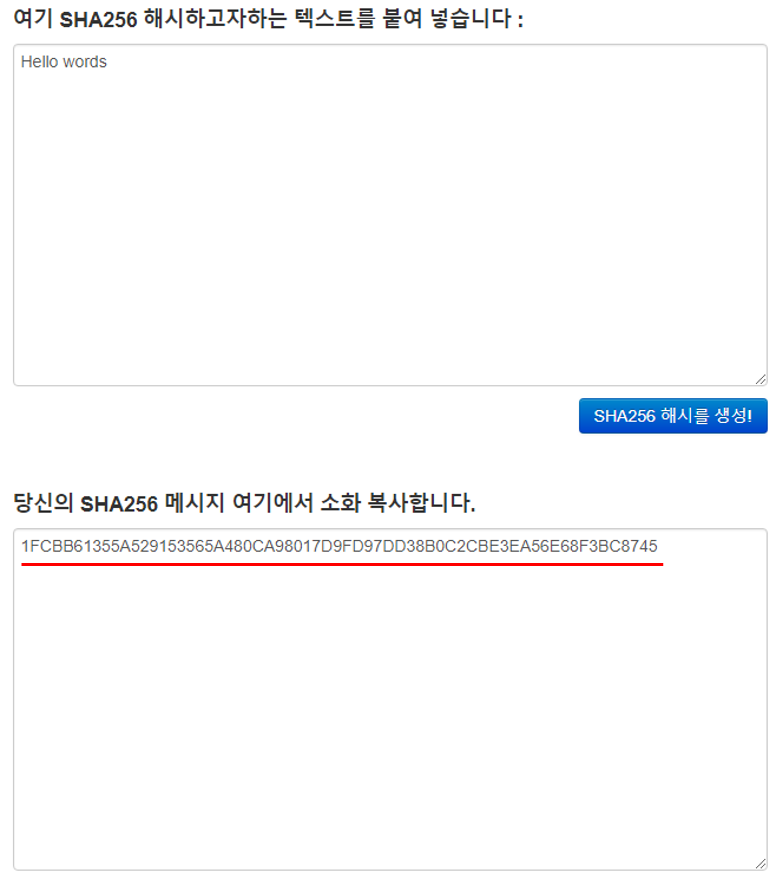
최초 데이터를 SHA256 형태의 해시값으로 변환한다.
가장 가까운 노드 2개를 한쌍으로 묶어 합친 후 해시값으로 변환한다.
계속해서 해시값으로 변환하여 마지막 하나가 남을때까지 이 과정을 반복한다.
<br/>
위의 그림처럼 각 해시된 결과값 TXID의 노드를 2개씩 짝지어 합친 후 다시 SHA256 함수를 통해 해시 값으로 변환하고 최종적으로 하나의 결과 값이 나올때 까지 이 과정을 계속해서 반복합니다. 최종적으로 남은 하나의 노드 값이 '머클루트' 결과 값이 되는겁니다!
다시 한번 정리해보면 아래와 같습니다.
블록헤더의 머클루트 값은 블록바디의 거래내역 정보인 TXID의 해시트리 결과 값이다.
머클루트의 역할은 각 거래 정보의(TXID)의 정보들이 변경되었는지에 대한 유효성을 검사하는 역할을 수행한다.
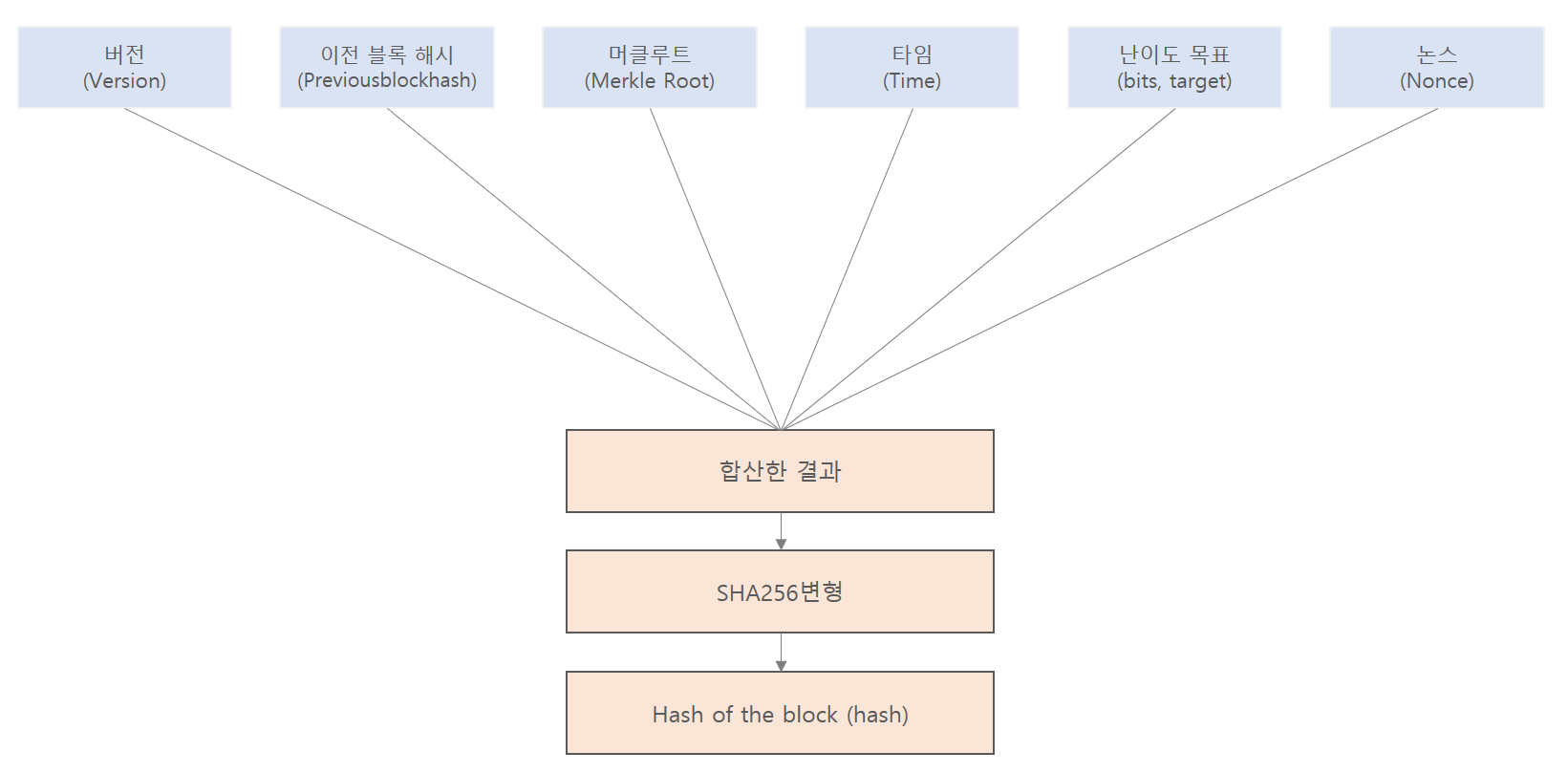
머클루트의 결과 값을 통해 블록 해시의 정보가 구성됨으로 그 블록의 유효성 또한 검사할 수 있다.
<
머클 루트 연산 과정
비트코인의 블록정보를 쉽게 볼 수 있도록 제공해주는 사이트인 '블록체인 인포' (https://blockchain.info/ko) 라는 사이트를 통해 블록 정보를 확인해보겠습니다. 제가 보고 있는 현 시점에서 블록체인 인포 사이트의 최신블록의 정보는 아래의 그림과 같이 #508186 입니다.
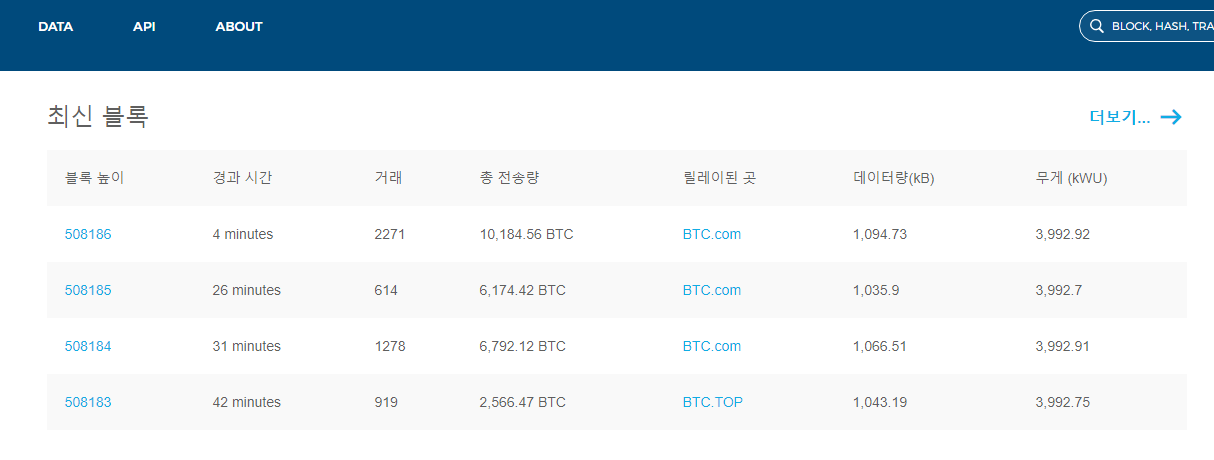
최신 블록인 #508186을 선택(클릭)하여 해당 블록의 정보를 자세히 살펴보겠습니다.
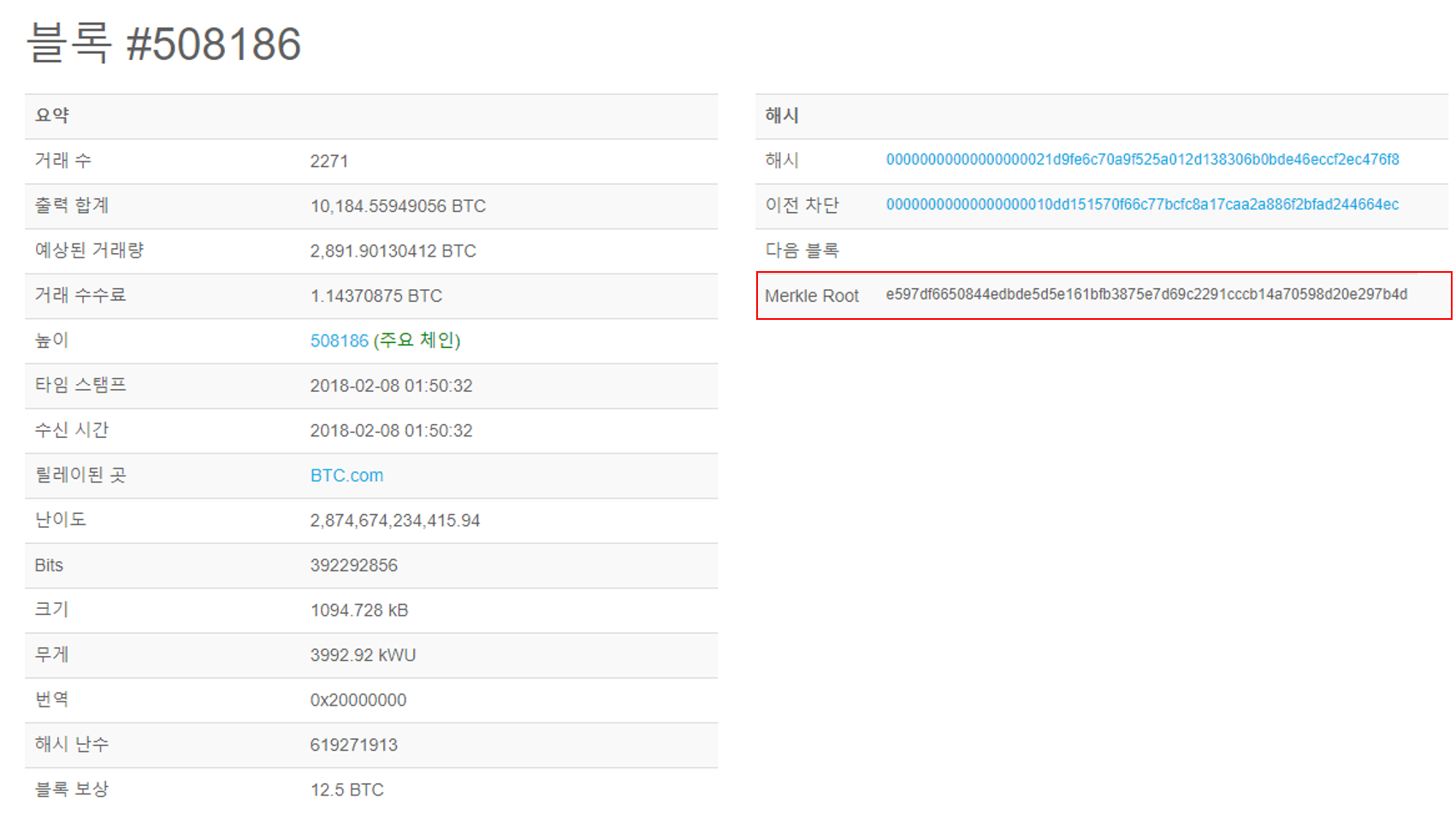
비트코인의 블록 정보를 확인해 볼 수 가 있습니다. 각 해당 요소들에 대한 설명에 대해서는 추후 계속적인 포스팅에 대해서 설명해 드리겠습니다. 이번 시간은 머클 루트 값을 구하는 과정을 테스트할 예정이기 때문에 다수의 거래정보가 있는 거래 리스트를 확인해 보겠습니다.
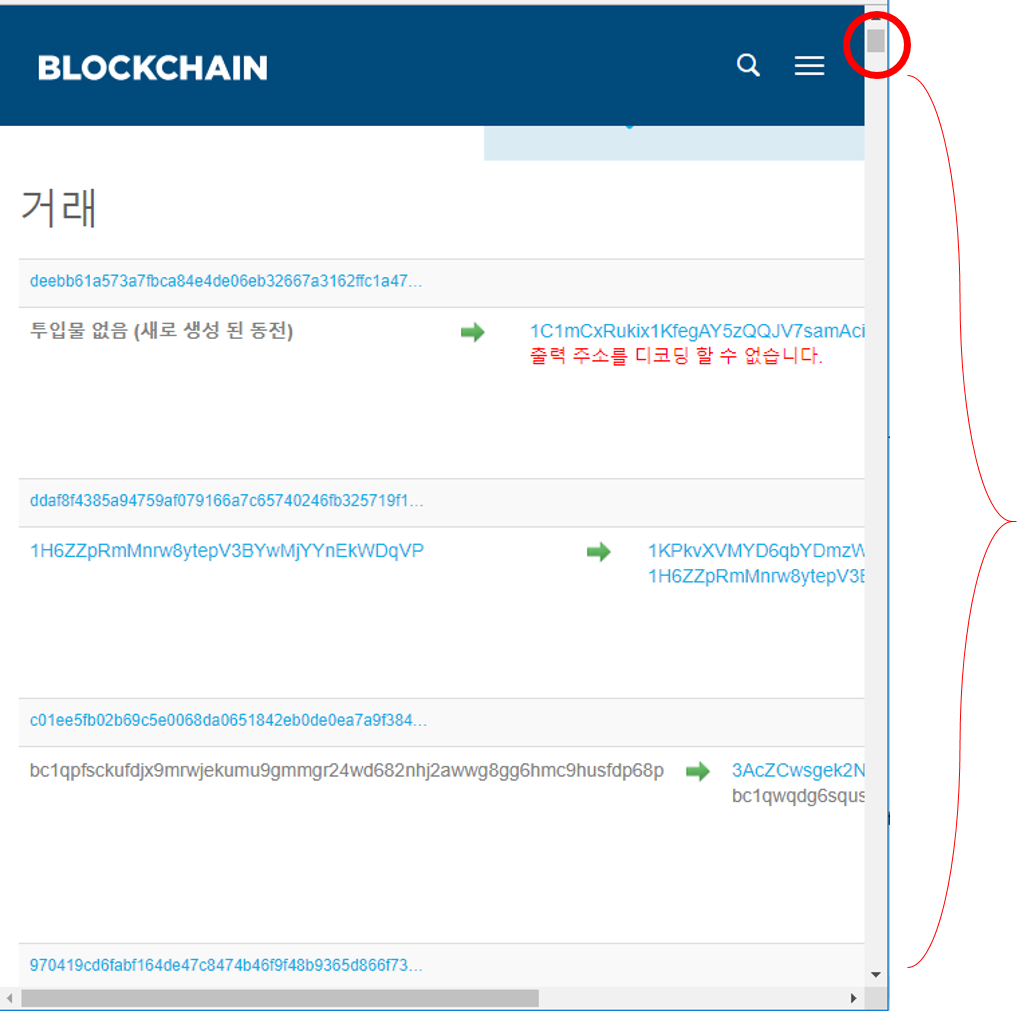
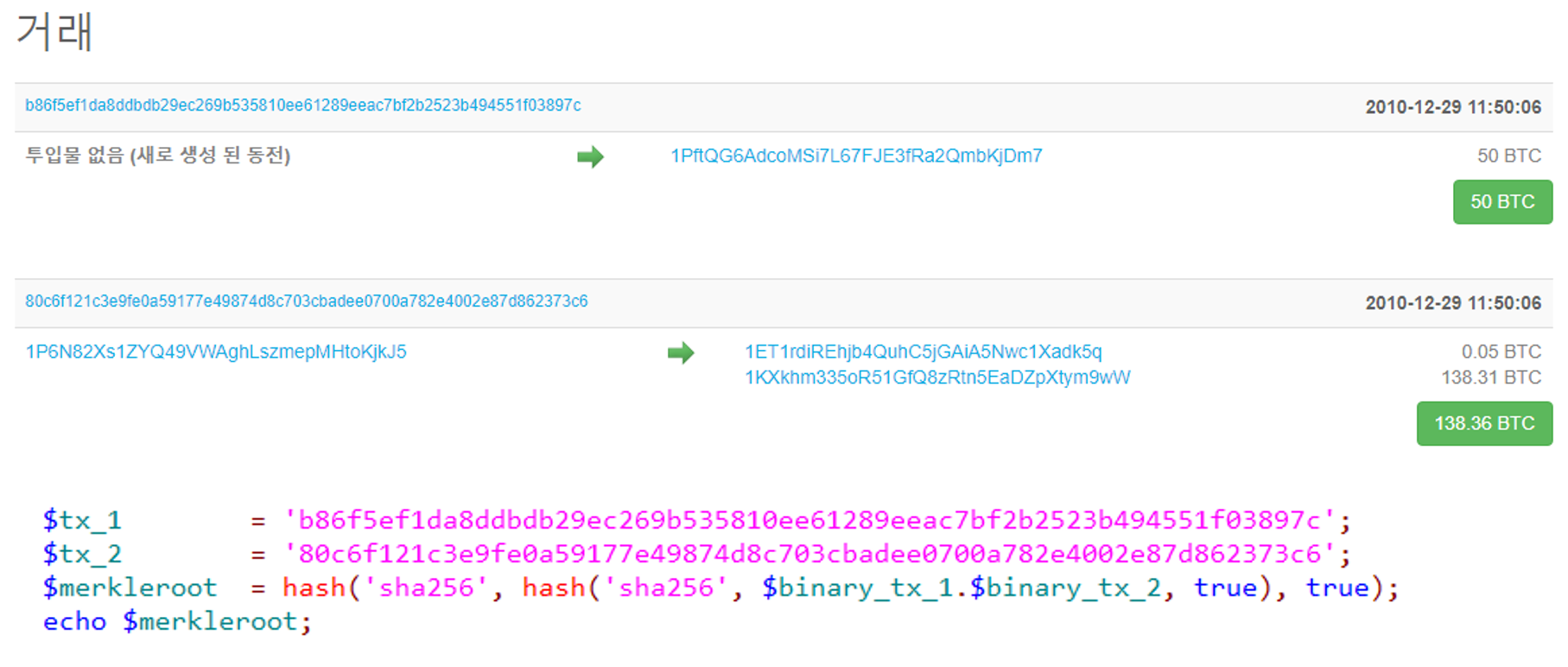
최신 블록은 위의 그림과 같이 정말 많은 거래 내역이 있기때문에, 테스트에 적합하지 않습니다. 거래 내역이 2건 내지 4건인 블록이 적당한 수치인것 같습니다. 마침 #99997번째 블록의 거래내역이 2건이기 때문에 해당 블록으로 테스트를 진행해보겠습니다. 해당 블록의 머클 루트와 거래정보는 아래의 그림과 같습니다.
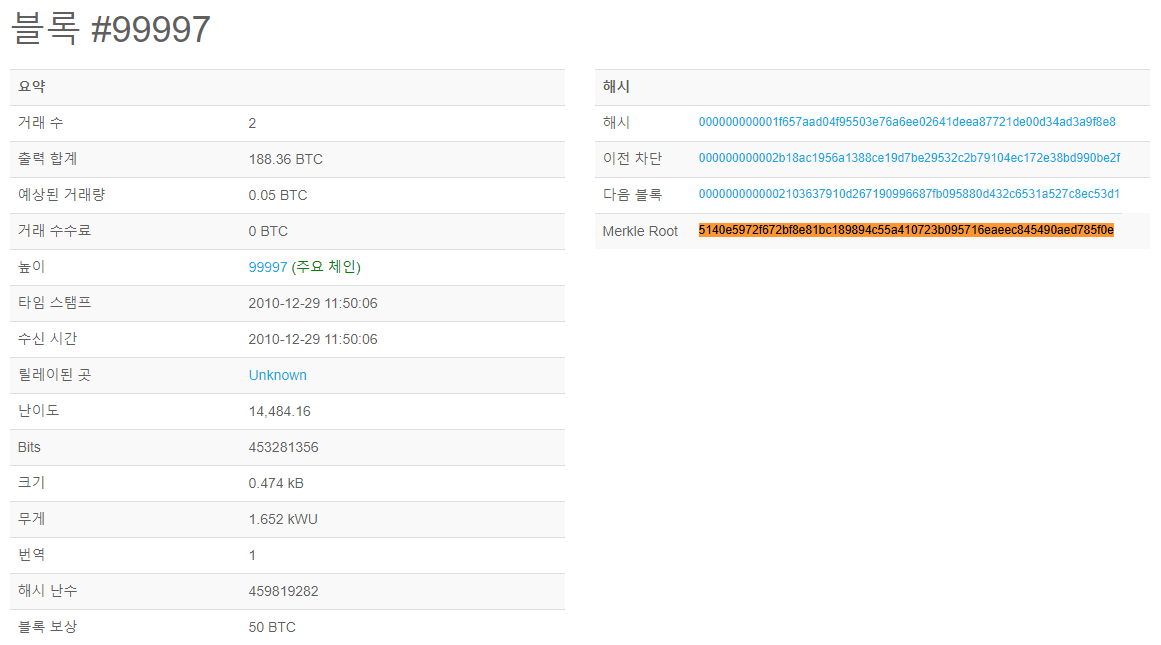
블록#99997의 머클 루트는 5140e5972f672bf8e81bc189894c55a410723b095716eaeec845490aed785f0e 이며, 거래 내역은 아래의 그림과 같습니다.
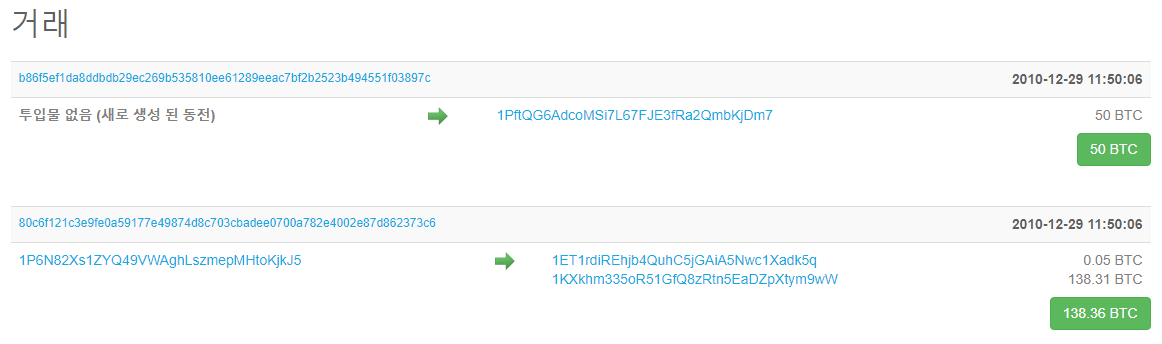
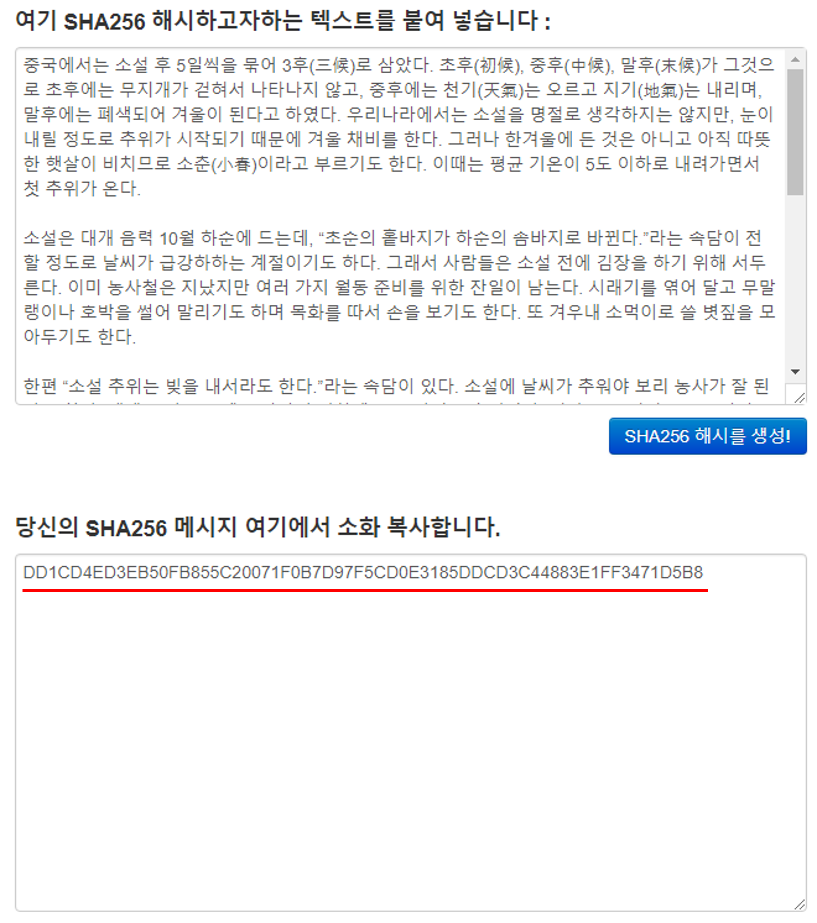
그럼 이제 거래 내역의 TXID 정보를 합산한 후 SHA256으로 변환하는 코드를 짜고 그 결과 값을 확인해 보겠습니다.
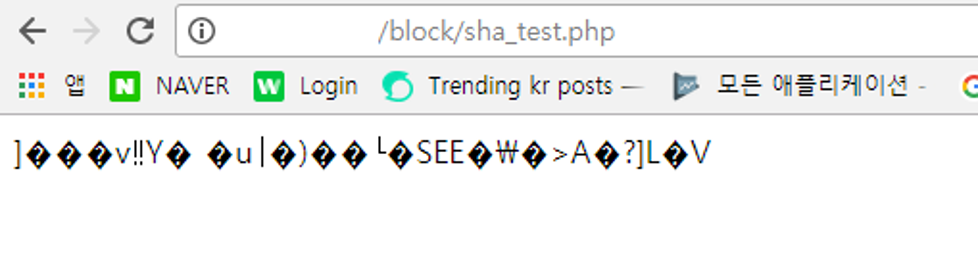
결과는 위의 그림처럼.. 이상한 결과가 나오고 있습니다... 여러분은 알고 계셨나요?? 머클루트는 이렇게 구하는게 아니라는걸요??
머클루트의 결과 값을 정확하게 구하기 위해서는 엔디안이라는 개념이 필요합니다, 컴퓨터에서 어떤 크기의 데이터를 메모리에 저장할 때 바이트 단위로 나누어 저장하며, CPU 아키텍처에 따라 바이트 저장 순서가 달라질 수 있기 때문에
리틀-엔디안과빅-엔디안방식으로 나누어 질 수 있습니다.
쉽게 생각해서 앞선 TXID를 컴퓨터가 이해하기 쉬운 형태로 변환한 후, 합산해야합니다. 우선 정확하게 머클 루트를 구하는 예제 코드를 보여드리겠습니다.
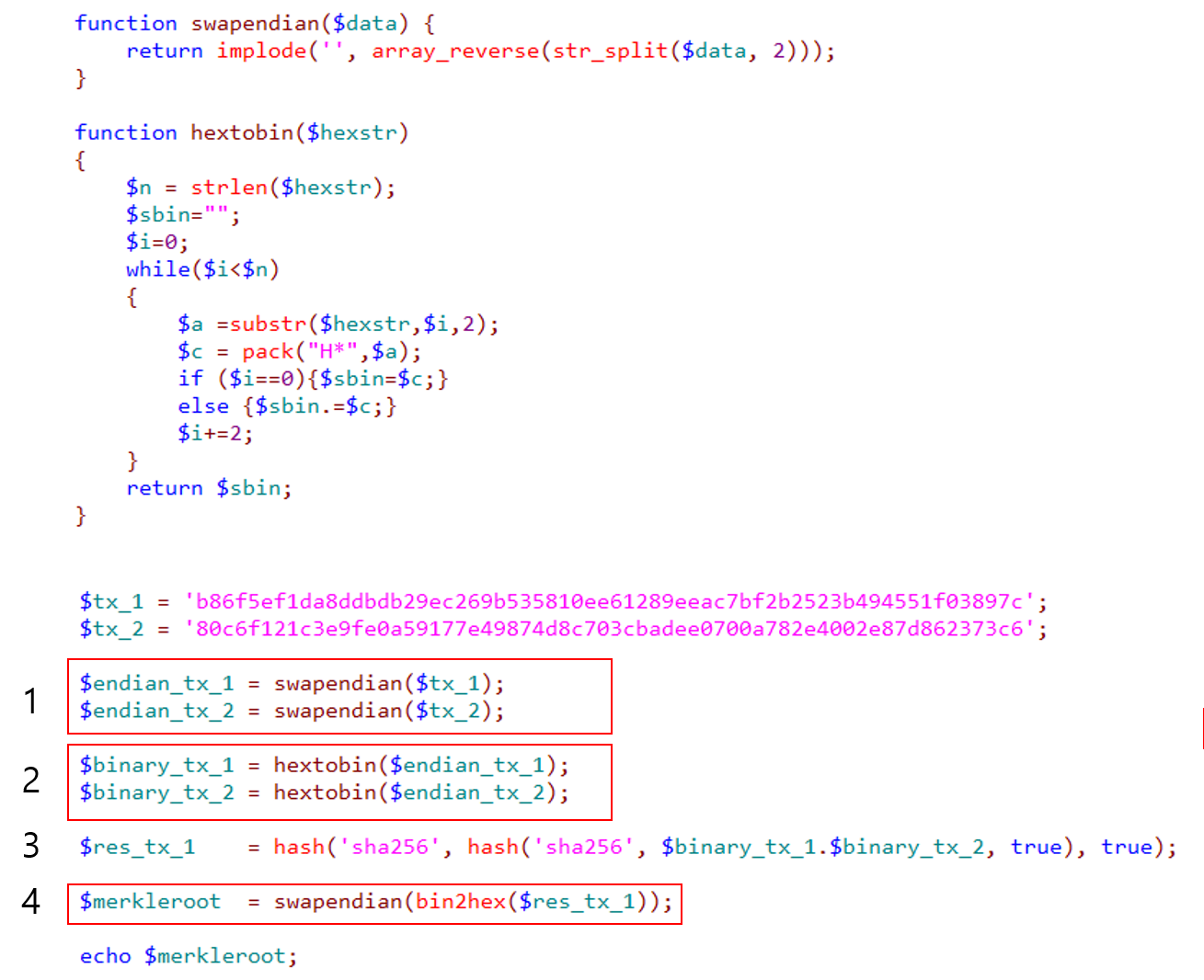
위의 예제 코드의 1번의 과정처럼 문자열을 스왑해주고, 2번의 과정으로 스왑된 데이터를 바이너리로 형태로 변경해야합니다. 그리고 이렇게 만들어진 데이터 TXID 1번과, TXID 2번의 문자열을 합산하는것이 아니라 이어 붙여준 후 해시 함수를 2번 연산해 주어야합니다. 이렇게 해시 함수를 통해 얻은 결과 값을 4번과정과 같이 다시 역으로 꺼내주면 정확한 머클 루트 값을 구할 수 있습니다.
위의 예제 소스의 결과는 아래와 같습니다.
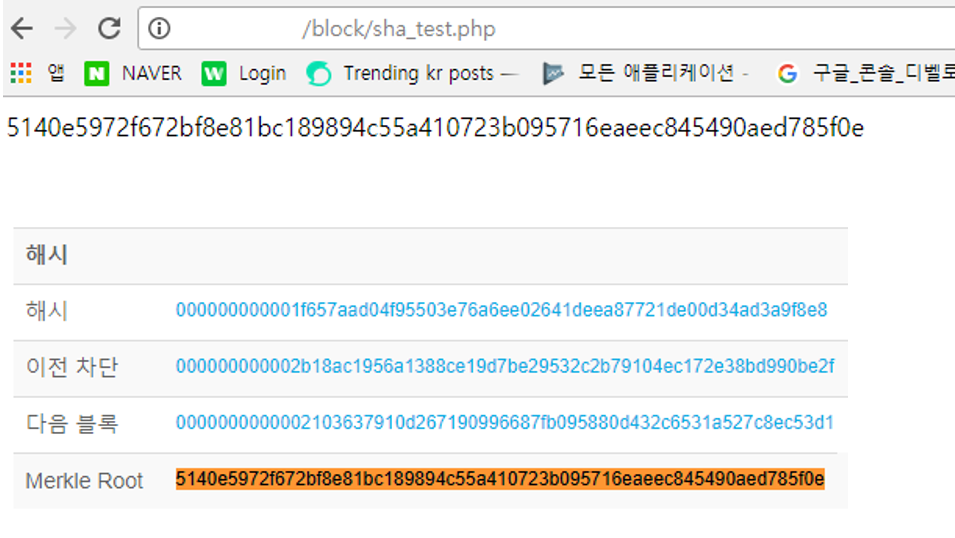
이렇게 해서 블록의 바디 정보인 TXID 정보를 토대로 머클 루트 결과 값을 만드는 과정을 확인해볼 수 있었습니다. 다음 포스팅에서는 비트코인의 블록헤더 정보는 무엇이고, 어떻게 값을 구하는지에 대해 알아보도록 하겠습니다.
추가로 머클 루트 구하는 방법을 테스트해보고 싶으신분은 아래의 링크를 통해 풀 코드를 확인해보시면 좋겠습니다. 해당 코드는 TXID의 양이 많더라도, 루프 문을 통하여 값을 구할 수 있도록 짜여진 코드입니다.
지금까지 긴 글 읽어주셔서 감사합니다!
[참고자료]
https://steemit.com/kr/@jayground8/hashmerkleroothttps://steemit.com/kr/@jsralph/merkle-treeshttps://steemit.com/kr/@twinbraid/5uzvbu-02http://twinbraid.blogspot.kr/2017/11/blog-post.html
'비트코인 > 블록체인 구조' 카테고리의 다른 글
| 블록 해시에 관한 정의 및 블록해시 연산과정 (2) | 2018.04.13 |
|---|---|
| 블록체인 및 블록 구성요소에 관한 정의 (0) | 2018.04.08 |
| 해시함수의 특징 및 정의 (1) | 2018.04.06 |




{kind=link}